데이터 세트
Kaggle에 공개된 국가별 사회경제적 지표 데이터 세트
https://www.kaggle.com/datasets/ashydv/country-socioeconomic-data
국가별 다양한 사회경제적 지표가 담겨 있는 데이트 세트를 분석하고 클러스터링을 통해 인사이트를 도출해 보겠습니다.
데이터 전처리
국가별 사회경제적 지표 데이터 세트는 167개국의 데이터를 포함하고 있으며 총 15개의 칼럼으로 구성되어 있습니다.
- country: 국가 이름
- child_mort: 출생아 1,000명당 5세 미만 아동 사망률
- exports: 총 GDP 대비 상품 및 서비스 수출 비율
- health: 총 GDP 대비 건강 지출 비율
- imports: 총 GDP 대비 상품 및 서비스 수입 비율
- income: 1인당 순수입
- inflation: 총 GDP 연간 성장률
- life_expec: 현재의 사망률 패턴이 유지될 경우 신생아의 평균 기대 수명
- total_fer: 현재의 연령별 출산율이 유지될 경우 여성 한 명당 태어날 자녀 수
- gdpp: 1인당 GDP
- region_1: 지역 구분 1
- region_2: 지역 구분 2
- continent: 대륙
- latitude: 위도
- longitude: 경도

print(df["country"].nunique() == df["country"].count())
먼저 중복된 국가가 없는지 확인한 후 데이터 전처리를 위해 칼럼별 결측값 개수를 확인해 보았습니다.

df["region_2"].dropna().unique()
region_2 칼럼에 101개의 결측값이 발견되었고 결측값이 아닌 데이터는 "Sub-Saharan Africa"과 "Latin America and the Caribbean" 두 가지 고유한 값으로 구성되어 있습니다.
"Sub-Saharan Africa"는 사하라 사막 이남의 아프리카 대륙 전체를 의미하며 "Latin America and the Caribbean"는 라틴 아메리카와 카리브해 지역을 의미합니다.
df["region_2"].fillna("Unknown", inplace=True)
region_2 칼럼의 결측값은 "Unknown"으로 채워주었습니다.
데이터 EDA
이제 각 지표의 데이터 분포와 지표 간의 상관관계를 분석해 보겠습니다.

히스토그램을 통해 5세 미만 아동 사망률(child_mort), 1인당 순수입(income), 총 GDP 연간 성장률(inflation), 1인당 GDP(gdpp)는 주로 낮은 값에 집중된 것을 확인할 수 있습니다.
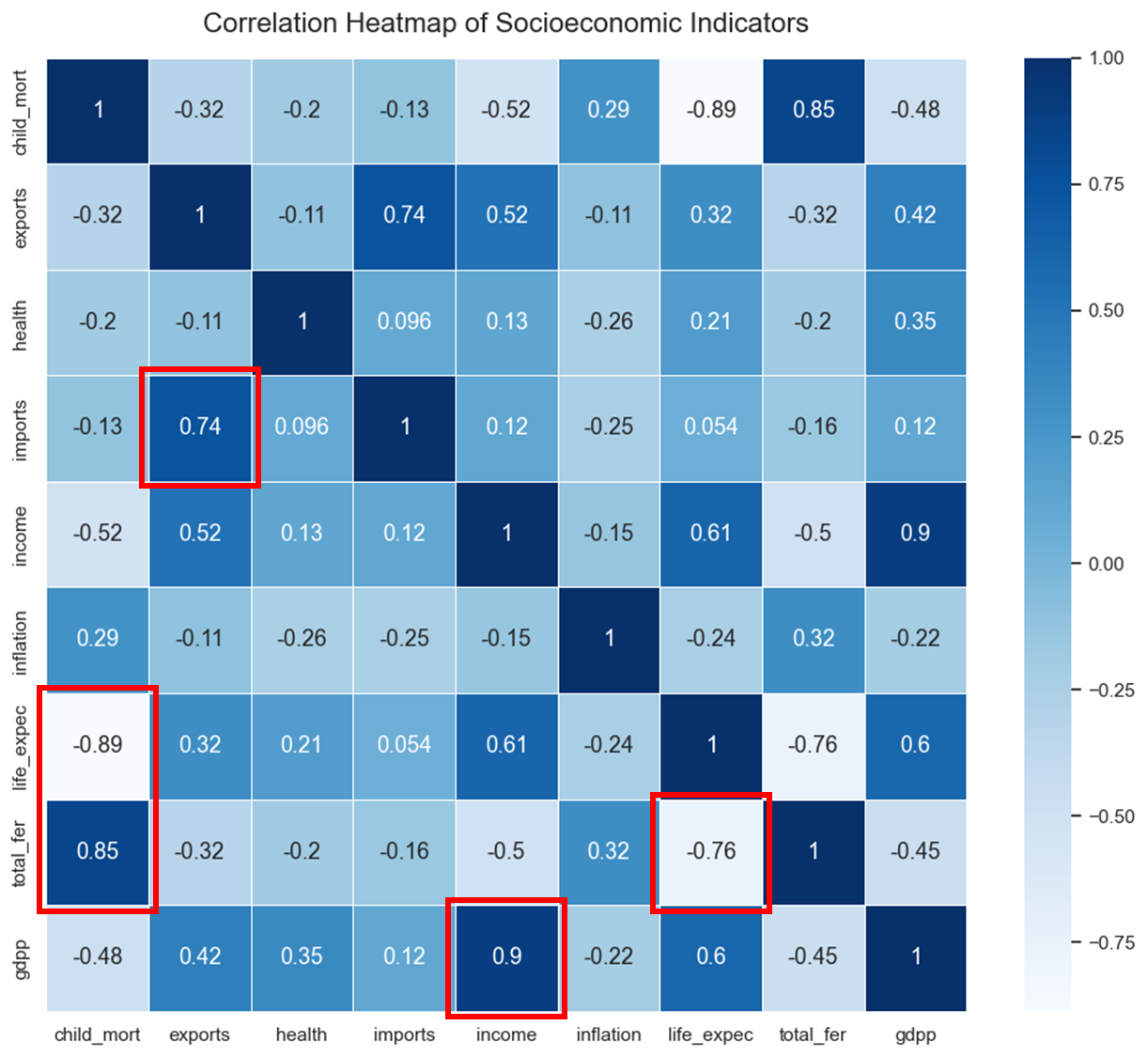
히트맵을 통해 지표 간의 상관관계를 살펴본 결과 여러 지표 간에 강한 상관관계가 나타났습니다.
1인당 순수입(income)과 1인당 GDP(gdpp) 간의 상관관계는 0.9, 5세 미만 아동 사망률(child_mort)과 여성 한 명당 태어날 자녀 수(total_fer) 간의 상관관계는 0.85, 상품 및 서비스 수출 비율(exports)과 상품 및 서비스 수입 비율(imports) 간의 상관관계는 0.74로 강한 양의 상관관계를 보이고 있습니다.
반면, 5세 미만 아동 사망률(child_mort)과 신생아의 평균 기대 수명(life_expec) 간의 상관관계는 -0.89, 신생아의 평균 기대 수명(life_expec)과 여성 한 명당 태어날 자녀 수(total_fer) 간의 상관관계는 -0.76으로 강한 음의 상관관계를 보입니다.
다음으로 대륙별 지표 평균을 비교해 보겠습니다.
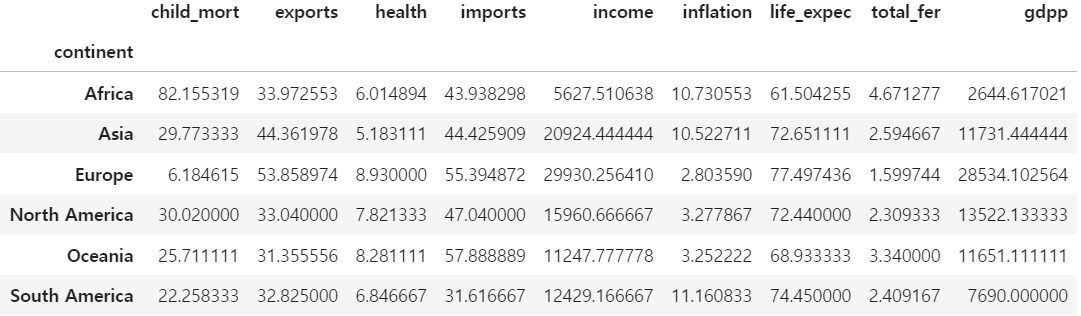

5세 미만 아동 사망률(child_mort), 1인당 순수입(income), 총 GDP 연간 성장률(inflation), 여성 한 명당 태어날 자녀 수(total_fer), 1인당 GDP(gdpp) 등의 지표에서 대륙 간의 차이가 두드러지게 나타났습니다. 이를 통해 각 대륙의 사회경제적 상황이 얼마나 상이한지를 예상해 볼 수 있습니다.
데이터 클러스터링
이제 계층적 군집화(Hierarchical Clustering)를 통해 비슷한 특징을 가진 데이터들을 그룹화하여 국가의 사회경제적 지표의 유사성과 차이점을 보다 명확하게 확인해 보겠습니다.
히트맵을 통해 확인한 지표 간의 상관관계를 바탕으로 다음 세 가지 기준으로 클러스터링을 진행해 보겠습니다.
1) 1인당 순수입(income)과 1인당 GDP(gdpp) 간의 클러스터링
2) 상품 및 서비스 수출 비율(exports)과 상품 및 서비스 수입 비율(imports) 간의 클러스터링
3) 5세 미만 아동 사망률(child_mort), 여성 한 명당 태어날 자녀 수(total_fer), 신생아의 평균 기대 수명(life_expec) 간의 클러스터링
1) 1인당 순수입(income)과 1인당 GDP(gdpp) 간의 클러스터링
먼저 클러스터 개수를 결정하기 위해 덴드로그램(dendrogram)과 실루엣 계수(silhouette score)를 시각화해 보겠습니다.
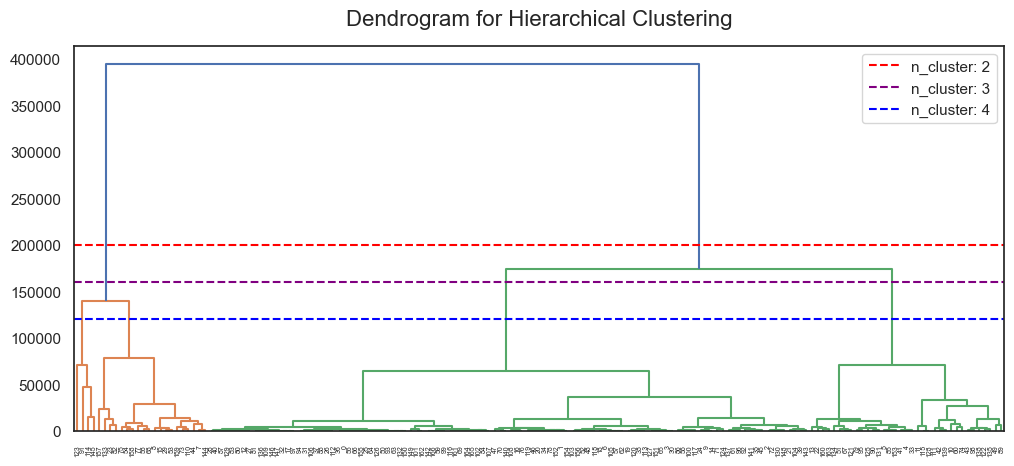
덴드로그램을 통해 클러스터의 계층 구조를 시각적으로 파악해 볼 수 있습니다. 클러스터 개수로 적절해 보이는 2, 3, 4개를 덴드로그램에 선으로 표시해 보았습니다.

클러스터가 2개에서 7개일 때까지의 실루엣 계수를 시각화한 결과 클러스터 개수가 2일 때 실루엣 계수가 가장 높은 것을 확인할 수 있습니다. 실루엣 계수의 값이 1에 가까울수록 데이터 포인트가 자신이 속한 클러스터와 잘 맞고 다른 클러스터와 명확히 구분된다는 것을 의미합니다.
덴드로그램과 실루엣 계수를 바탕으로 클러스터 개수를 2로 선택하여 계층적 군집 모델인 Agglomerative Clustering을 학습시켜 보겠습니다.


학습 결과를 violinplot으로 시각화한 결과 1인당 순수입(income)과 1인당 GDP(gdpp)가 모두 낮은 국가들은 Label 0으로, 상대적으로 높은 국가들은 Label 1로 구분되었습니다. Label 1의 분포가 넓은 범위에 걸쳐 있는 것을 통해 Label 1은 다양한 경제적 지표를 가진 국가들이 포함되어 있으며 같은 Label에 포함된 국가들 사이에도 경제적으로 차이가 있음을 보여줍니다.

각 Label에 속하는 대륙의 수를 확인해 보니 대부분의 국가는 Label 0으로 분류되며 아프리카와 남아메리카 대륙의 모든 국가는 Label 0으로 분류되는 것을 알 수 있습니다.
그렇다면 대한민국은 어느 Label로 분류될까요?
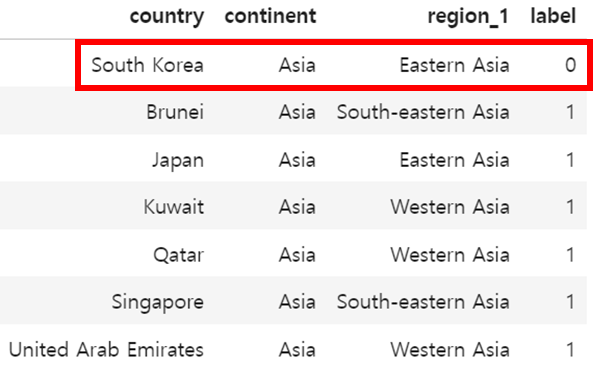
대한민국은 Label 0으로 분류됩니다. 대한민국과 같은 대륙인 아시아에 속하는 국가 중 Label 1에 해당하는 국가들을 살펴보니 대부분 석유 생산국이라는 공통점을 확인할 수 있습니다.
2) 상품 및 서비스 수출 비율(exports)과 상품 및 서비스 수입 비율(imports) 간의 클러스터링
두 번째 클러스터링에서 클러스터 개수를 결정하기 위해 덴드로그램(dendrogram)과 실루엣 계수(silhouette score)를 시각화해 보았습니다.

클러스터 개수로 적절해 보이는 2, 3, 4일 때를 덴드로그램에 선으로 표시했습니다.

클러스터 개수가 2에서 7일 때까지의 실루엣 계수를 시각화해 보니 클러스터가 2개일 때 실루엣 계수가 가장 높습니다. 덴드로그램과 실루엣 계수를 바탕으로 클러스터 개수를 2로 선택하여 계층적 군집 모델인 Agglomerative Clustering을 학습시켜 보겠습니다.


학습 결과를 violinplot으로 시각화한 결과 Label 0과 Label 1이 확실하게 구분된 것을 확인할 수 있습니다. 상품 및 서비스 수출 비율(exports)과 상품 및 서비스 수입 비율(imports)이 모두 낮은 국가들은 Label 0, 모두 높은 국가들은 Label 1로 구분되었습니다.

각 Label에 속하는 대륙의 수를 확인해 보았더니 대부분의 국가는 Label 0으로 분류되고 Label 1에는 3개의 국가만 포함된 것을 확인할 수 있습니다.

대한민국도 역시 Label 0으로 분류되었고 Label 1에는 룩셈부르크, 몰타, 싱가포르가 포함되어 있습니다.
3) 5세 미만 아동 사망률(child_mort), 여성 한 명당 태어날 자녀 수(total_fer), 신생아의 평균 기대 수명(life_expec) 간의 클러스터링
마지막 조건에 대해 클러스터링을 진행해 보겠습니다.

마지막 클러스터링에서도 클러스터 개수로 적절해 보이는 2, 3, 4일 때를 덴드로그램에 선으로 표시해 보았습니다.

2에서 7일 때까지의 클러스터 개수에 대한 실루엣 계수를 시각화해 보니 클러스터가 2개일 때 실루엣 계수가 가장 높습니다. 덴드로그램과 실루엣 계수를 바탕으로 클러스터 개수를 2로 선택하여 계층적 군집 모델인 Agglomerative Clustering을 학습시켜 보겠습니다.
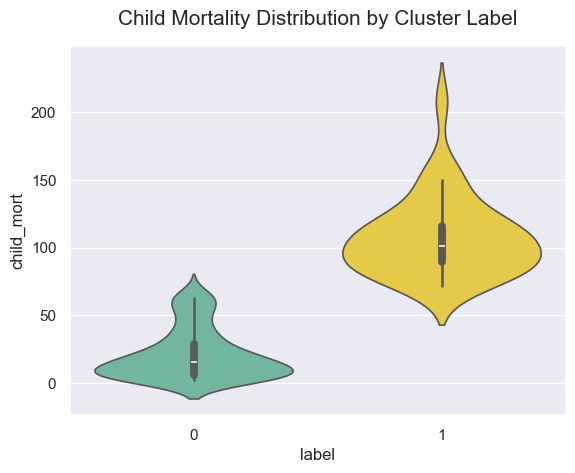


결과를 확인해 보면 각 Label에 대해 어느 정도 구분된 것을 확인할 수 있습니다. 5세 미만 아동 사망률(child_mort)이 낮고 여성 한 명당 태어날 자녀 수(total_fer)도 적으며 신생아의 평균 기대 수명(life_expec)이 높은 국가들은 Label 0, 그 반대의 경우인 국가들은 Label 1로 구분되었습니다.

각 Label에 속하는 대륙의 수를 확인해 보니 대부분의 국가는 Label 0에 포함되지만, 아프리카 대륙의 국가들은 Label 1에 다수 포함된 것을 확인할 수 있습니다.

대한민국은 Label 0으로 분류되어 있습니다. 대한민국과 같은 대륙인 아시아에 속하는 국가 중 Label 1로 분류된 국가들을 살펴보니 대부분 개발도상국에 포함되는 국가인 것을 확인할 수 있습니다.
인사이트 도출 및 결론
지금까지 다음 세 가지 기준으로 클러스터링을 진행해 보았습니다.
1) 1인당 순수입(income)과 1인당 GDP(gdpp) 간의 클러스터링
2) 상품 및 서비스 수출 비율(exports)과 상품 및 서비스 수입 비율(imports) 간의 클러스터링
3) 5세 미만 아동 사망률(child_mort), 여성 한 명당 태어날 자녀 수(total_fer), 신생아의 평균 기대 수명(life_expec) 간의 클러스터링
첫 번째 클러스터링 결과를 통해 대한민국이 경제지표가 높지 않은 그룹으로 분류되는 것을 확인할 수 있습니다. 반면, 같은 아시아 국가인 일본과 싱가포르는 경제지표가 높은 그룹에 포함되었습니다. 이를 통해 대한민국은 경제적으로 많은 성장을 이루었지만, 세계적으로 선진국 대열에 합류하기 위해서는 여전히 더 많은 발전이 필요하다는 것을 확인할 수 있습니다.
2024년 4월 발표 기준으로 세계 1인당 GDP 순위를 참고하면 대한민국은 31위, 일본은 34위, 싱가포르는 5위를 차지하고 있습니다. 올해 처음으로 대한민국이 1인당 GDP 순위에서 일본을 앞질렀습니다. 이러한 최근 데이터를 반영하여 클러스터링을 다시 진행하면 새로운 인사이트를 얻을 수 있을 것으로 기대됩니다.
두 번째 클러스터링 결과를 통해 룩셈부르크, 몰타, 싱가포르 3개의 국가를 제외한 국가는 상품 및 서비스 수출과 수입 비율이 모두 낮은 그룹으로 분류되는 것을 확인했습니다. 이를 통해 대부분의 국가가 수출 비율이 높거나 수입 비율이 높은 구조 혹은 내수 중심의 경제 구조 가지고 있다는 것을 예상할 수 있습니다. 룩셈부르크는 금융 서비스 중심, 싱가포르는 무역과 물류 중심, 몰타는 관광 중심의 경제 구조로 되어 있어 이들 국가는 필연적으로 높은 수출입 비율을 보이는 것으로 유추해 볼 수 있습니다.
마지막 클러스터링 결과로 여성 한 명당 태어날 자녀 수가 높지만, 신생아 평균 기대 수명이 낮고 아동 사망률이 높은 국가들이 아프리카에 다수 포함된 것을 확인할 수 있습니다. 이는 아프리카 대륙이 사회적으로 많은 지원이 필요하다는 것을 보여줍니다. 특히, 선진국들을 포함한 다양한 국가들에서 의료 시설과 보건 프로그램을 지원한다면 아프리카 대륙의 아동 사망률을 낮추는 데 큰 도움이 될 것입니다.
GitHub
https://github.com/hkle2/socioeconomic_indicators_project
GitHub - hkle2/socioeconomic_indicators_project: Socioeconomic Indicators Clustering Project
Socioeconomic Indicators Clustering Project. Contribute to hkle2/socioeconomic_indicators_project development by creating an account on GitHub.
github.com
'데이터 분석 > 프로젝트' 카테고리의 다른 글
| Cookie Cats A/B 테스트 데이터 분석 (0) | 2024.08.08 |
|---|---|
| 넷플릭스 영화 데이터 분석 (7) | 2024.08.02 |
| Kaggle Spaceship titanic 경진대회 (0) | 2024.07.21 |
| 고령 운전자 교통사고 데이터 분석 (0) | 2024.07.15 |
| Olist 이커머스 데이터 분석 프로젝트 (0) | 2024.07.04 |