데이터 세트
Kaggle에 공개된 넥플릭스 영화 데이터 세트
https://www.kaggle.com/datasets/luiscorter/netflix-original-films-imdb-scores
2021년 6월 1일까지 공개된 넷플릭스 영화(다큐멘터리, 스페셜 포함)를 위키피디아 페이지에서 웹 스크래핑한 다음 IMDB(Internet Movie DataBase) 점수 데이터 세트와 통합
최근 다양한 OTT 서비스의 등장에도 불구하고 넷플릭스의 구독자 수는 계속해서 증가하고 있습니다. 이와 함께 구독료도 지속적으로 상승하고 있습니다. 이러한 상황에서 넷플릭스의 높은 구독료에도 사용자들이 서비스를 계속 이용하도록 하기 위해서는 더욱 매력적인 콘텐츠를 제공해야 합니다. 따라서 넷플릭스의 영화 데이터를 분석하여 앞으로 어떤 방향으로 콘텐츠를 제작해야 할지 알아보겠습니다.
데이터 전처리
이번 프로젝트에서 사용한 넷플릭스 영화 데이터 세트는 584개의 데이터를 포함하고 있으며 영화 제목(Title), 영화 장르(Genre), 최초 공개일(Premiere), 영화 상영 시간(Runtime), IMDB 점수(IMDB Score), 언어(Language)의 총 6개의 칼럼으로 구성되어 있습니다.
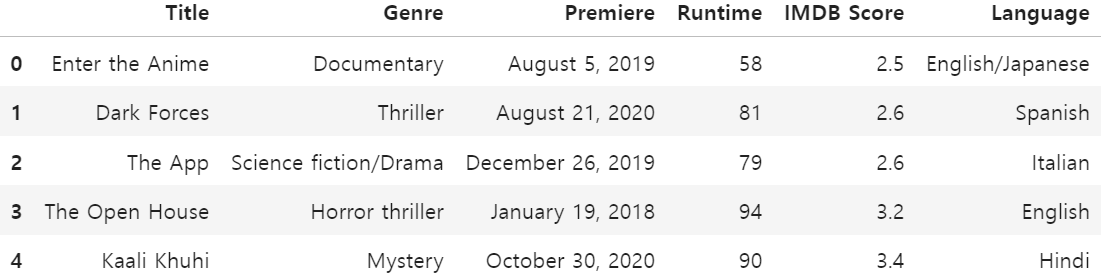
데이터 세트의 각 칼럼에 대한 기본 정보와 기술 통계량은 다음과 같습니다.

데이터 전처리를 진행하기 위해 칼럼별 결측값 개수를 확인해 보겠습니다.

결측값이 없는 보기 드문 데이터 세트입니다!! 결측값 처리는 넘어가고 데이터 형식을 일관되게 만들고 파생 변수를 생성하도록 하겠습니다.
먼저, Genre 칼럼의 데이터를 자세히 살펴보면 데이터의 형식이 일관되지 않은 것을 확인할 수 있습니다. 여러 장르가 있는 경우 장르를 구분하는 구분자가 상이하거나, 동일한 장르가 다르게 적혀있는 경우도 있습니다. 따라서 데이터의 형식을 일관되게 만들어 주기 위해 특정 값을 치환하고 장르 구분자를 "/"로 통일했으며 장르의 첫 글자만 대문자로 나머지는 소문자로 바꾸는 작업을 진행했습니다.
def replace_genre(genre):
genre_replacements = {
"Science fiction": "Science_fiction",
"Science Fiction": "Science_fiction",
"Dark comedy": "Dark_comedy",
"Black comedy": "Black_comedy",
"Christian musical": "Christian_musical",
"Coming-of-age": "",
"Hidden-camera": "Hidden_camera",
"Making-of": "Making_of",
"Mentalism special": "Mentalism_special",
"One-man show": "One_man_show",
"Stop Motion": "Stop_Motion",
"Teen drama": "Teen_drama",
"Teenage drama": "Teen_drama",
"Variety show": "Variety_show",
"Variety Show": "Variety_show"
}
genre = re.sub(r"\bfilm\b", "", genre, flags=re.IGNORECASE)
pattern = re.compile("|".join(re.escape(key) for key in genre_replacements.keys()))
def replace(match):
return genre_replacements[match.group(0)]
transformed_genre = pattern.sub(replace, genre).strip().replace(" ", " ")
transformed_genre = re.sub(r"[\s,/-]+", "/", transformed_genre)
transformed_genre = "/".join(g.capitalize() for g in transformed_genre.split("/"))
return transformed_genre
df.Genre = df.Genre.apply(replace_genre)Premiere 칼럼도 일부 데이터의 형식이 상이하여 "년도-월-일" 형식으로 통일시켜 줬습니다. Premiere 칼럼의 데이터로 연도, 월, 요일, 분기 정보를 얻을 수 있어 Year, Month, DayOfWeek, Quarter 칼럼을 생성했습니다.
df.Premiere = df.Premiere.str.replace(".", ",", regex=False)
df["Premiere"] = pd.to_datetime(df.Premiere)
df["Year"] = df.Premiere.dt.year
df["Month"] = df.Premiere.dt.month
df["DayOfWeek"] = df.Premiere.dt.strftime("%a")
df["Quarter"] = df.Premiere.dt.quarter
df["Premiere"] = df.Premiere.dt.strftime("%Y-%m-%d")데이터 분석
이제 전처리를 완료한 데이터를 사용해서 분석해 보도록 하겠습니다.
여러분들은 어떤 장르의 영화를 선호하시나요? 저의 경우 특정한 장르를 가리지 않고 영화를 좋아하기 때문에 다른 사람들은 어떤 장르의 영화를 선호하는지 궁금했습니다. IMDB 평균 점수가 높은 영화 장르를 확인해 보겠습니다.

Concert, Making of, One man show, Mentalism special 순으로 높은 평균 IMDB 점수가 나온 것을 확인할 수 있습니다. 이제 점수가 높은 장르의 공개된 영화 개수가 어떤지 함께 확인해 보겠습니다.

IMDB 점수 순위가 2위인 Making of 장르의 영화는 2개, 4위인 Mentalism special 장르의 영화는 1개입니다. 이렇게 소수의 영화만 포함하고 있는 장르가 많아 영화 장르 간의 평균 IMDB 점수를 비교하기는 어려워 보입니다.
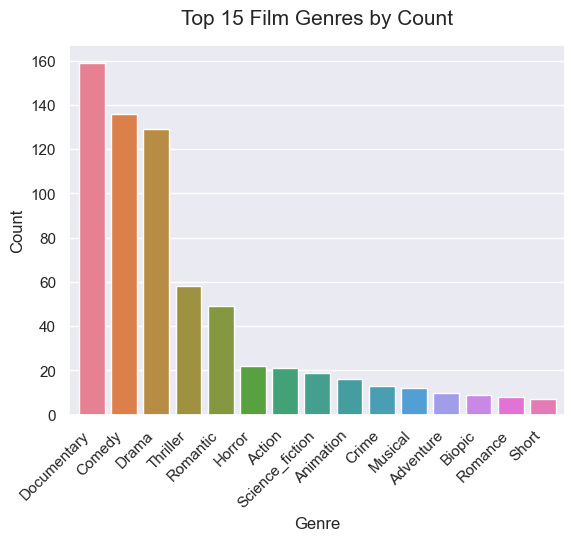
IMDB 평균 점수가 높은 상위권의 영화 장르와 공개된 영화 개수가 많은 장르를 비교해 보니 IMDB 점수와 공개된 영화 개수 사이에는 상관관계가 없다고 판단됩니다. 정말 그런지 확인해 보겠습니다.

IMDB 평균 점수와 영화 개수 사이의 상관관계를 시각화한 scatterplot을 그려보면 다수의 영화 장르가 20개 이하의 개수에 분포하고 있는 것을 알 수 있습니다. 20개 이상의 영화를 포함하는 장르를 보면 영화 개수가 많을수록 평균 IMDB 점수도 높아지는 경향이 있는 것처럼 보이지만 확실하게 결론을 내리기는 어렵습니다. 따라서 회귀선을 그려 확인해 보겠습니다.
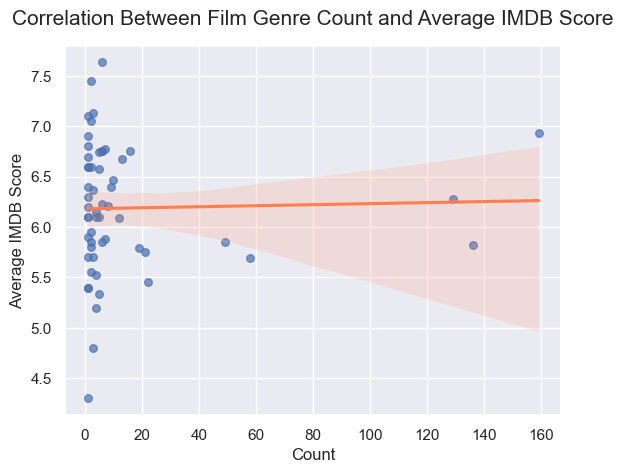
회귀선의 신뢰 구간이 넓은 것은 것을 보면 데이터의 수가 적어 예측이 불확실하다는 것을 알 수 있습니다. 영화 개수와 평균 IMDB 점수 사이의 상관관계를 구체적인 수치로 확인해 보겠습니다.
correlation, p_value = stats.pearsonr(count_avg_score_df["Count"], count_avg_score_df["Average IMDB Score"])
print(f'피어슨 상관계수: {correlation:.2f}')
print(f'p-value: {p_value:.2f}')
영화 개수와 IMDB 점수 간의 피어슨 상관계수는 0.03로 매우 낮으며 p-value는 0.85로 유의수준인 0.05보다 크기 때문에 두 변수 간에는 통계적으로 유의미한 상관관계가 없는 것으로 판단됩니다. 따라서 긍정적으로 평가된 장르의 영화라고 해서 넷플릭스에서 많이 제작하고 있지는 않다는 것을 알 수 있습니다.
이제 사람들이 선호하는 영화를 조금 다른 관점에서 살펴보도록 하겠습니다. 넷플릭스 영화 수의 추이를 살펴보겠습니다.

2021년 6월까지의 데이터만 있기 때문에 2021년을 제외하면 연도별 공개된 영화 수는 계속해서 증가하고 있는 추이를 확인할 수 있습니다.
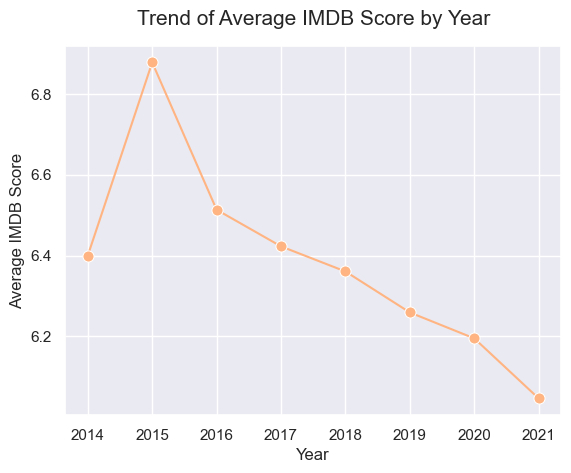
반면에 연도별 평균 IMDB 점수는 계속해서 하락하는 추세를 보입니다. 점점 더 많은 넷플릭스 영화가 제작되는 상황에서 넷플릭스가 더욱 성장하기 위해서는 사람들에게 긍정적인 평가를 받는 영화를 제작하는 것이 중요할 것입니다.
평일보다는 주말에 넷플릭스 시청 시간이 더 길기 때문에 주말에 영화를 공개한다거나 휴가를 많이 가는 연초, 연말을 노려 공개하는 등 공개일이 영화에 대한 사람들의 선호도를 높이는 데 영향을 미칠 수 있을 것으로 생각됩니다. 따라서 영화 공개일을 분기별, 월별, 요일별로 나누어 데이터를 확인해 보겠습니다.
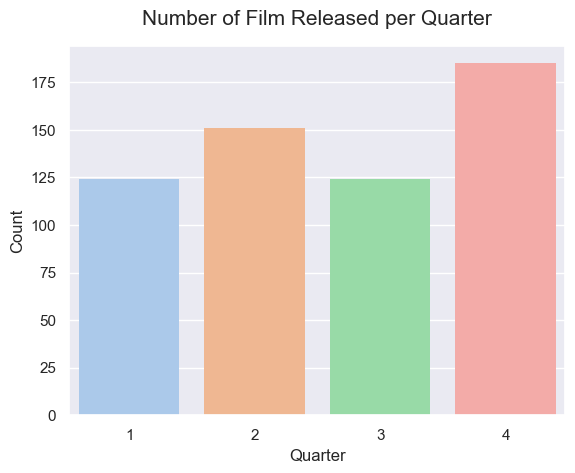
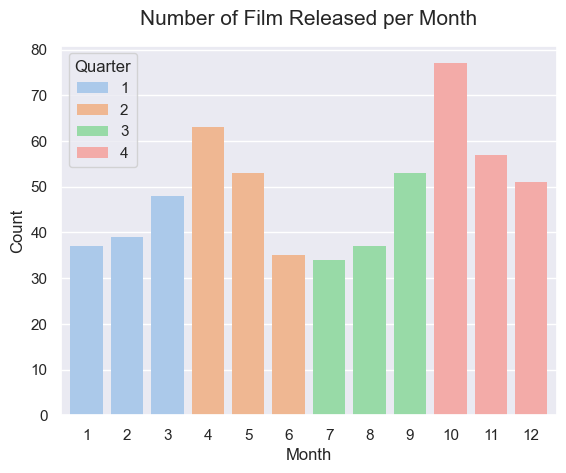

그래프를 확인해 보면 4분기에 공개된 영화가 가장 많으며 그중에서도 10월에 가장 많이 공개되었고 금요일에 공개된 영화가 압도적으로 많았습니다. 넷플릭스가 많은 영화를 금요일에 공개하는 이유가 금요일에 공개된 영화가 높은 IMDB 점수를 얻기 때문일 것이라고 가정하고 two sample t-test를 진행했습니다.
1. 가설 설정
귀무가설 : 금요일에 공개된 영화와 금요일에 공개되지 않은 영화의 평균 IMDB 점수 차이는 0이다.
대립가설 : 금요일에 공개된 영화와 금요일에 공개되지 않은 영화의 평균 IMDB 점수 차이는 0보다 크다. (단측 검정)
2. 등분산 검정
fri_scores = df[df.DayOfWeek == "Fri"]["IMDB Score"]
other_scores = df[df.DayOfWeek != "Fri"]["IMDB Score"]
statistics, p_value = stats.levene(fri_scores, other_scores)
if p_value > 0.05:
print("등분산")
else:
print("이분산")
3. two sample t-test
t_statistic, p_value = stats.ttest_ind(
a=fri_scores,
b=other_scores,
alternative="greater",
equal_var=False
)
if p_value < 0.05:
print(f"p-value : {p_value}, 귀무가설 기각")
else:
print(f"p-value : {p_value}, 대립가설 기각")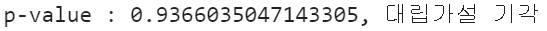
two sample t-test 결과 p-value는 0.94로 평균 차이가 유의미하지 않아 대립가설이 기각되었습니다. 따라서 금요일에 공개된 영화가 높은 IMDB 점수를 얻는다는 결론을 내릴 수 없습니다.

요일별 IMDB 점수의 분포를 시각화하여 확인해 본 결과 금요일에 공개된 영화의 점수가 다른 요일에 비해 높은 점수대에 분포하고 있지 않다는 것을 다시 한번 확인할 수 있습니다.
인사이트 및 액션 아이템 제시
넷플릭스에서 제작하는 영화 수가 계속해서 증가하고 있지만 평균 IMDB 점수는 하락 추세를 보입니다. 사용자의 선택에 대한 다양성이 많아지고 있음에도 IMDB 점수가 낮아지는 추세는 영화 콘텐츠의 다양성보다는 퀄리티가 중요하다는 것을 시사합니다. 따라서 사용자의 의견을 적극적으로 반영하여 콘텐츠의 품질을 높이는 것이 필요합니다.
또한, 2021년 6월까지 대부분의 영화가 금요일에 공개되었습니다. 이는 특정 요일에 대한 편향을 초래하며 영화의 노출 기회를 제한할 수 있습니다. 영화 공개 일정을 금요일에 집중하지 않고 다양한 요일에 분산시켜 영화의 노출을 극대화하고 다양한 고객층을 겨냥하여 높은 IMDB 점수를 노려볼 수 있을 것입니다.
마지막으로 사용자 리뷰 데이터를 분석하여 영화 선호도에 영향을 주는 요소를 정확히 파악하고 이를 다음 영화 제작에 반영하는 것이 중요할 것입니다. 사용자 리뷰 데이터에서 도출된 피드백을 바탕으로 더 나은 콘텐츠를 제작하는 데 활용해야 합니다.
GitHub
https://github.com/hkle2/netflix_project
GitHub - hkle2/netflix_project: netflix dataset analysis project
netflix dataset analysis project. Contribute to hkle2/netflix_project development by creating an account on GitHub.
github.com
'데이터 분석 > 프로젝트' 카테고리의 다른 글
| 국가별 사회경제적 지표 데이터 클러스터링 (5) | 2024.08.30 |
|---|---|
| Cookie Cats A/B 테스트 데이터 분석 (0) | 2024.08.08 |
| Kaggle Spaceship titanic 경진대회 (0) | 2024.07.21 |
| 고령 운전자 교통사고 데이터 분석 (0) | 2024.07.15 |
| Olist 이커머스 데이터 분석 프로젝트 (0) | 2024.07.04 |