데이터 세트
Kaggle에 공개된 Cookie Cats A/B 테스트 데이터 세트
https://www.kaggle.com/datasets/mursideyarkin/mobile-games-ab-testing-cookie-cats
Cookie Cats라는 퍼즐 게임을 운영하는 회사에서 플레이어를 게이트 레벨 30 또는 게이트 레벨 40 그룹에 랜덤으로 배치한 후 두 그룹의 A/B 테스트 결과를 기록한 데이터 세트
A/B 테스트는 두 가지 버전을 비교하여 어떤 버전이 더 나은 성과를 내는지 통계적으로 분석하는 실험 방법입니다. Cookie Cats 퍼즐 게임에서 게이트 위치를 기준으로 두 그룹으로 나누어 진행한 A/B 테스트 결과를 분석하여 어떤 그룹이 게임 플레이를 더 오래 지속할 확률이 높은지 확인해 보겠습니다. 2016년에 출시된 Cookie Cats 게임은 현재 신규 플레이어의 유입이 줄어든 상황입니다. 따라서 드물게 유입되는 신규 플레이어가 게임을 오래 즐길 수 있도록 하여 게임의 경쟁력을 높이는 것이 중요합니다. 이를 위해 A/B 테스트 결과 데이터를 분석하여 최적의 게임 설계를 위한 게이트 배치 전략을 도출해 보겠습니다.
데이터 전처리
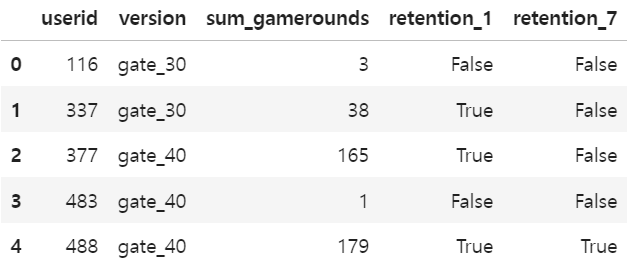
Cookie Cats A/B 테스트 데이터 세트는 90,189명 플레이어의 A/B 테스트 결과를 포함하고 있으며 플레이어 ID번호(userid), 배치된 그룹(version), 총 게임 라운드 수(sum_gamerounds), 1일 차 접속 여부(retention_1), 7일 차 접속 여부(retention_7) 총 5개의 칼럼으로 구성되어 있습니다.
데이터 전처리를 진행하기 위해 칼럼별 결측값 개수를 확인해 보겠습니다.

결측값이 없어 결측값 처리는 넘어가고 데이터 형식을 일관되게 만들고 불필요한 데이터는 삭제하겠습니다.
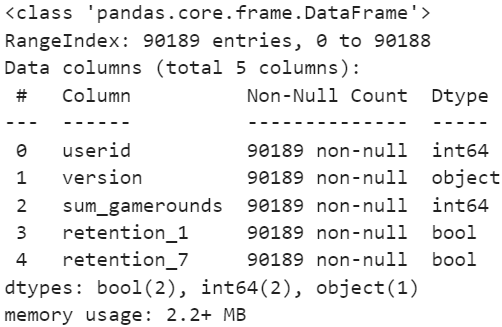
데이터 세트의 각 칼럼에 대한 기본 정보를 확인해 보니 userid 칼럼은 정수형 데이터, retention_1과 retention_7 칼럼은 논리형 데이터로 구성되어 있습니다. userid 칼럼의 데이터는 플레이어의 고유한 ID 번호이기 때문에 문자열 형식으로 변경하고 retention_1, retention_7 칼럼의 데이터는 True, False를 정수형 데이터 형식으로 변경했습니다.
print(df["userid"].nunique() == df["userid"].count())
중복된 플레이어의 데이터가 있는지 다음 코드로 확인해 보니 True의 결과가 나와 중복 데이터가 없는 것을 확인했습니다.
이제 A/B 테스트 결과의 신뢰성을 높이기 위한 데이터 전처리를 위해 총 게임 라운드 수에 따른 플레이어 수를 시각화해 보겠습니다.


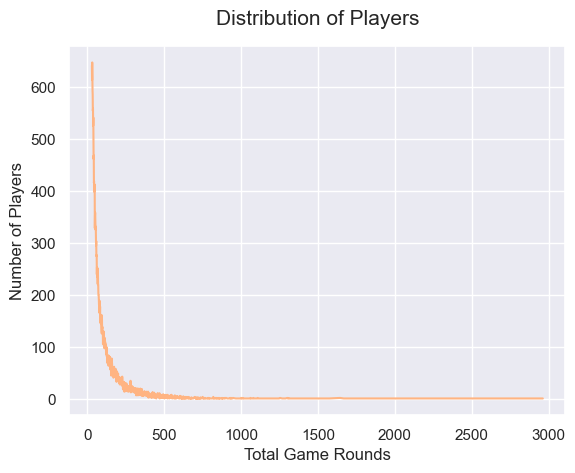
왼쪽의 그래프는 전체 플레이어의 총 게임 라운드 수 분포를 시각화한 것이고 오른쪽 그래프는 총 게임 라운드 수가 50 이하인 플레이어의 총 게임 라운드 수 분포를 시각화한 것입니다.
print(f"총 게임 라운드 수가 0인 플레이어 수 : {len(df[df["sum_gamerounds"] == 0]):,}명")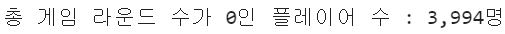
실제로 대부분의 플레이어가 게임을 한 번도 플레이하지 않은 것을 알 수 있습니다. 게임을 설치하고 한 번도 플레이하지 않은 플레이어가 3,994명으로 상당히 많다는 것을 알 수 있습니다.
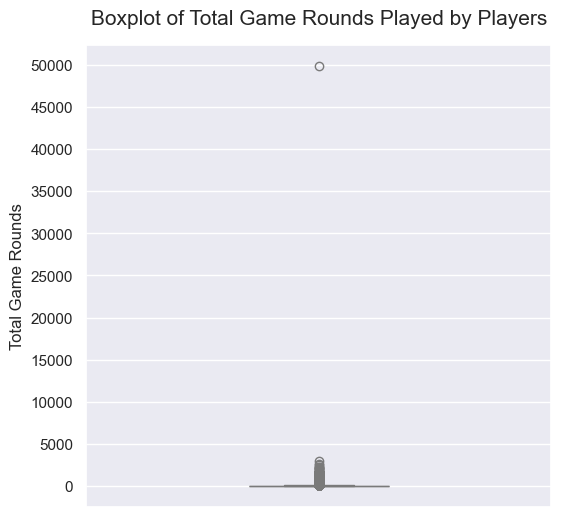
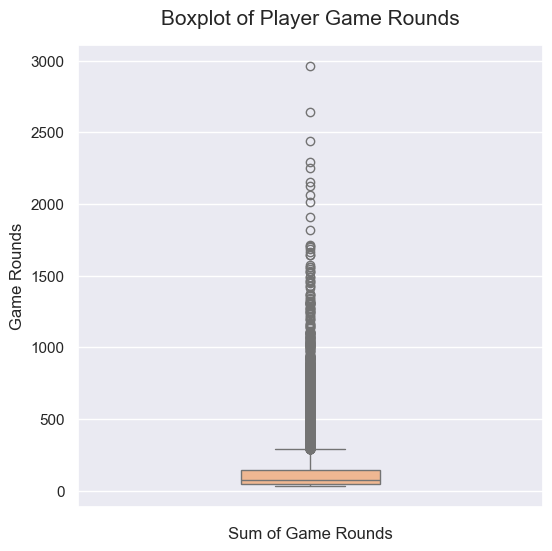
boxplot을 통해 플레이어의 총 게임 라운드 수의 분포를 확인한 결과 한 명의 플레이어가 50,000회에 가까운 매우 많은 라운드의 플레이를 했지만, 나머지 대부분의 플레이어는 5,000회도 플레이하지 못한 것을 확인할 수 있습니다.
print(f"총 게임 라운드 수 최댓값 : {df["sum_gamerounds"].max():,}회")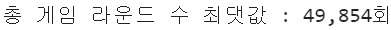
가장 많은 플레이를 한 플레이어는 49,854회 플레이를 했습니다. 실제 Cookie Cats 게임을 플레이해 본 결과 한 라운드에 최소 1분 정도의 시간이 소요되는 것을 확인하였고 따라서 이 플레이어는 실제로 게임을 플레이했다기보다는 매크로를 사용했거나 데이터에 오류가 있던 것으로 판단됩니다.
또한, 대부분의 플레이어가 게이트가 위치한 레벨 30과 레벨 40에 도달하기 전에 플레이를 중단하기 때문에 총 게임 라운드 수가 30 또는 40회보다 적은 플레이어의 데이터는 A/B 테스트 결과에 대한 영향이 제한적일 수 있습니다.
이제 게임을 설치만 하고 한 번도 플레이하지 않은 플레이어와 49,854로 불가능한 총 게임 라운드 수를 보유한 플레이어의 데이터를 삭제하겠습니다. 추가로 A/B 테스트 결과의 정확성을 높이기 위해 총 게임 라운드 수가 30 미만인 플레이어의 데이터도 삭제하도록 하겠습니다.
df = df[(df["sum_gamerounds"] != 0) & (df["sum_gamerounds"] != df["sum_gamerounds"].max())]
df = df[df["sum_gamerounds"] >= 30]
다음은 최종적으로 전처리를 마친 데이터의 총 게임 라운드 수에 따른 플레이어 수 분포와 플레이어의 총 게임 라운드 수 분포 그래프입니다.
데이터 분석
Cookie Cats 게임을 플레이해 본 경험이 있으신가요? Cookie Cats는 동일한 모양의 쿠키를 연결하여 터뜨리는 게임으로 라운드마다 클리어해야 할 조건을 줍니다. 저는 개인적으로 게임을 설치만 하고 한 번도 플레이하지 않은 플레이어들의 심정을 이해해 버리고 말았습니다. 🫠
A/B 테스트에 사용된 retention_1과 retention_7 칼럼의 데이터로 게임 설치 후 1일 차에 접속한 플레이어의 수와 게임 설치 후 7일 차에 접속한 플레이어 수를 확인해 보겠습니다.

1일 차에는 접속했지만 7일 차에는 접속하지 않은 플레이어 수가 14,489명으로 가장 높은 비율을 차지하고 1일 차에는 접속하지 않았지만 7일 차에는 접속한 플레이어 수가 2,278명으로 가장 적은 것을 확인할 수 있습니다.
이제 A/B 테스트를 위한 게이트 레벨 30 그룹과 게이트 레벨 40 그룹의 비율을 확인해 보겠습니다.
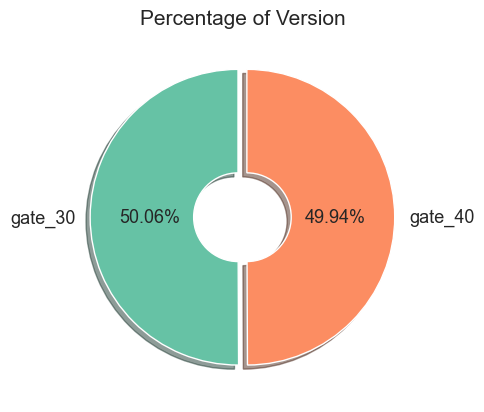
게이트 레벨이 30인 그룹(gate_30)은 50.06%, 게이트 레벨이 40인 그룹(gate_40)은 49.94%로 비슷한 비율로 나눈 것을 확인했습니다. 그렇다면 그룹에 따른 게임 라운드 수의 평균은 어떤지 살펴보겠습니다.
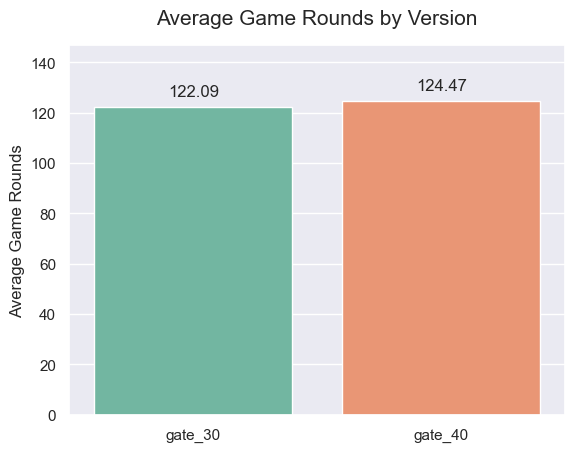
gate_30의 평균 게임 라운드 수는 122.09회, gate_40의 평균 게임 라운드 수는 124.47회입니다. gate_40의 평균 게임 라운드 수가 gate_30보다 더 높다는 것을 알 수 있지만, 이 차이가 통계적으로 유의미한지 여부를 단순히 평균을 비교하는 것만으로는 판단하기가 어렵습니다. 따라서 t-test를 사용하여 gate_30과 gate_40의 평균 게임 라운드 수의 차이가 통계적으로 유의미한지 검정해 보겠습니다.
귀무가설과 대립가설을 설정하고 p-value를 계산해 보겠습니다.
- 귀무가설 : gate_30 그룹과 gate_40 그룹의 평균 게임 라운드 수의 차는 0이다.
- 대립가설 : gate_30 그룹과 gate_40 그룹의 평균 게임 라운드 수의 차는 0이 아니다. (양측 검정)
gate_30 = df[df.version == "gate_30"]["sum_gamerounds"]
gate_40 = df[df.version == "gate_40"]["sum_gamerounds"]
stat, p_value = stats.levene(gate_30, gate_40)
if p_value < 0.05:
t_stat, p_value = stats.ttest_ind(
a=gate_30,
b=gate_40,
alternative="two-sided",
equal_var=False
)
print("levene test 결과 : 이분산")
else:
t_stat, p_value = stats.ttest_ind(
a=gate_30,
b=gate_40,
alternative="two-sided",
equal_var=True
)
print("levene test 결과 : 등분산")
if p_value < 0.05:
print(f"p-value : {round(p_value, 4)}, 귀무가설 기각")
print("gate_30과 gate_40의 평균 게임 라운드 수는 다르다.")
else:
print(f"p-value : {round(p_value, 4)}, 대립가설 기각")
print("gate_30과 gate_40의 평균 게임 라운드 수는 같다.")
p-value가 0.1284로 유의수준인 0.05보다 크기 때문에 대립가설이 기각되고 gate_30 그룹과 gate_40 그룹의 평균 게임 라운드 수가 같다는 귀무가설이 채택되었습니다. 따라서 두 그룹 간의 평균 게임 라운드 수의 차이가 유의미하지 않다는 결론을 내릴 수 있습니다.
게임 설치 후 1일 차 접속 여부에 따른 플레이어의 비율을 확인해 보겠습니다.

1일 차에는 80.14%의 플레이어가 접속한 것을 확인할 수 있습니다. 이 비율을 다시 그룹별로 나눠 살펴보겠습니다.

gate_30은 80.10%, gate_40은 80.18%로 1일 차 접속률이 비슷한 것을 알 수 있습니다. 그러나 단순히 비율을 비교하는 것만으로는 이 차이가 통계적으로 유의미한지 여부를 판단할 수 없습니다. 따라서 chi_squared test를 사용하여 배치된 그룹(version)과 1일 차 접속 여부(retention_1) 두 변수가 서로 독립인지 검정해 보겠습니다.
귀무가설과 대립가설을 설정하고 p-value를 계산해 보겠습니다.
- 귀무가설 : version과 retention_1 두 변수는 독립이다.
- 대립가설 : version과 retention_1 두 변수는 독립이 아니다.
table1 = pd.crosstab(df["version"], df["retention_1"])
chi2_stat, p_value, _, expected = chi2_contingency(table1)
pd.DataFrame(expected, index=table1.index, columns=table1.columns)
if p_value < 0.05:
print(f"p-value : {round(p_value, 4)}, 귀무가설 기각")
print("version과 retention_1 두 변수는 독립이 아니다.")
else:
print(f"p-value : {round(p_value, 4)}, 대립가설 기각")
print("version과 retention_1 두 변수는 독립이다.")p-value가 0.8619로 유의수준인 0.05보다 크기 때문에 대립가설이 기각되고 version과 retention_1 두 변수는 독립이라는 귀무가설이 채택되었습니다. 따라서 플레이어가 배치된 그룹과 1일 차 접속 여부는 서로 관련이 없다는 결론을 내릴 수 있습니다.
다음으로 게임 설치 후 7일 차 접속 여부에 따른 플레이어의 비율을 확인해 보겠습니다.
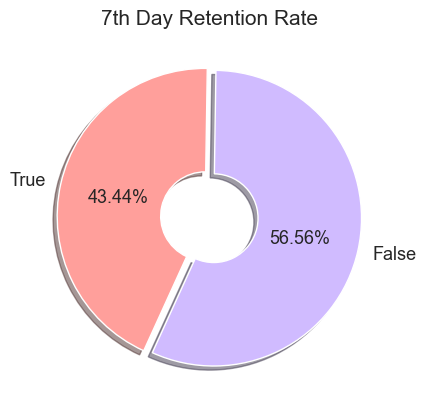
7일 차 플레이어의 접속률은 43.44%로 1일 차 플레이어의 접속률에 비해 많이 감소한 것을 확인할 수 있습니다. 이 비율을 그룹별로 다시 나누어 확인해 보겠습니다.

gate_30은 43.87%, gate_40은 43.00%로 7일 차 접속률이 비슷한 것을 알 수 있습니다. 그러나 단순히 비율을 비교하는 것만으로는 이 차이가 통계적으로 유의미한지 여부를 판단하기가 어렵습니다. 따라서 chi_squared test를 사용하여 배치된 그룹(version)과 7일 차 접속 여부(retention_7) 두 변수가 서로 독립인지 검정해 보겠습니다.
귀무가설과 대립가설을 설정하고 p-value를 계산해 보겠습니다.
- 귀무가설 : version과 retention_7 두 변수는 독립이다.
- 대립가설 : version과 retention_7 두 변수는 독립이 아니다.
table2 = pd.crosstab(df["version"], df["retention_7"])
chi2_stat, p_value, _, expected = chi2_contingency(table2)
pd.DataFrame(expected, index=table2.index, columns=table2.columns)
if p_value < 0.05:
print(f"p-value : {round(p_value, 4)}, 귀무가설 기각")
print("version과 retention_7 두 변수는 독립이 아니다.")
else:
print(f"p-value : {round(p_value, 4)}, 대립가설 기각")
print("version과 retention_7 두 변수는 독립이다.")p-value가 0.1118로 유의수준인 0.05보다 크기 때문에 대립가설이 기각되고 version과 retention_7 두 변수는 독립이라는 귀무가설이 채택되었습니다. 따라서 플레이어의 배치된 그룹과 7일 차 접속 여부는 서로 관련이 없다는 결론을 내릴 수 있습니다.
현재까지의 분석 결과를 바탕으로 gate_30의 1일 차 접속률은 gate_40보다 약간 낮지만 7일 차 접속률은 약간 더 높은 것을 알 수 있습니다. 이는 장기적으로 보면 gate_30이 접속률을 높이는 데 효과적일 수 있다는 가설을 제기할 수 있습니다. 이 가설이 통계적으로 유의미한지 조금 더 구체적으로 검토하기 위해 bootstrapping 방법을 사용하여 검증해 보겠습니다.
Bootstrapping 방법은 주어진 데이터로부터 여러 번의 반복 샘플링을 통해 표본 분포를 추정하고 이를 기반으로 통계적 추정을 수행하는 기법입니다. 데이터의 분포를 가정하지 않고도 랜덤으로 샘플을 추출하여 통계적 성질을 평가할 수 있습니다.
이제 A/B 테스트를 위한 두 그룹(gate_30, gate_40)의 1일 차 및 7일 차 접속률을 bootstrapping 방법을 통해 추정하고 각 그룹 간의 접속률의 차이를 분석해 보겠습니다.

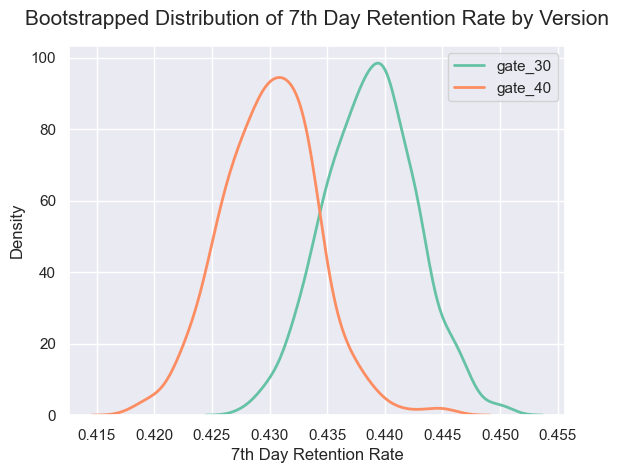
Bootstrapping 결과를 시각화해 보니 1일 차에서는 gate_40의 접속률이 gate_30의 접속률보다 더 높은 경향을 보였지만 7일 차 접속률에서는 gate_30이 gate_40보다 접속률이 높은 경향이 나타났습니다.
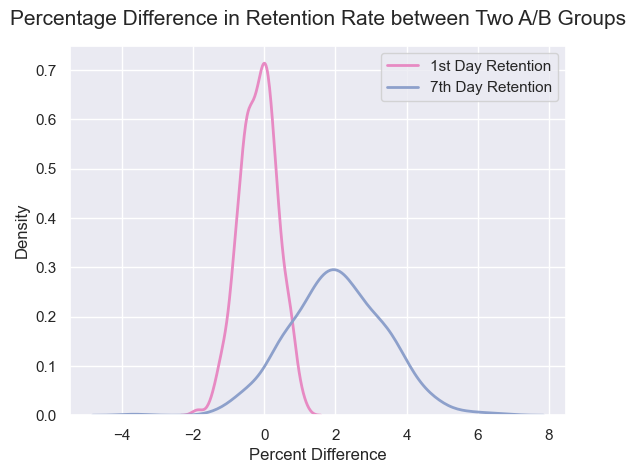
마지막으로 gate_30의 접속률이 gate_40의 접속률에 비해 얼마나 더 높은지를 백분율 분포로 시각화했습니다. x축이 양수일 경우 gate_30의 접속률이 gate_40의 접속률보다 높은 것을 의미하고 x축이 음수일 경우에는 반대의 경우를 의미합니다. 위의 그래프를 통해 1일 차보다 7일 차에 gate_40보다 gate_30의 접속률이 높아진 것을 확인할 수 있습니다.
prob_1 = (boot1_df["diff"] > 0).sum() / len(boot1_df["diff"])
prob_7 = (boot7_df["diff"] > 0).sum() / len(boot7_df["diff"])
print(f"gate_30이 gate_40보다 1일차 접속률이 높을 확률 : {round(prob_1, 2) * 100}% \
\ngate_30이 gate_40보다 7일차 접속률이 높을 확률 : {round(prob_7, 2) * 100}% ")
gate_30이 gate_40보다 1일 차 접속률이 높을 확률은 40%지만 7일 차 접속률이 높을 확률은 94%로 나타났습니다.
인사이트 도출 및 결론
Cookie Cats 게임의 게이트 위치에 따른 A/B 테스트 결과를 다각도로 분석해 보았습니다. t-test를 통해 A/B 테스트를 위한 두 그룹(gate_30, gate_40) 간에 평균 게임 라운드 수에는 유의미한 차이가 없는 것을 확인했습니다. 이는 게이트 위치 변경이 플레이어의 참여도에 영향을 주지 않았다는 것을 의미합니다.
다음으로 chi_squared test를 통해 플레이어가 배치된 그룹(version)과 1일 차 접속률(retention_1)의 독립성과 플레이어가 배치된 그룹(version)과 7일 차 접속률(retention_7)도 독립성을 확인했습니다. 게이트 위치 변경이 단기적인 관점에서 플레이어의 접속 유지에 영향을 주지 않는다는 것을 의미합니다.
그러나 bootstrapping 방법을 통해 조금 더 심층적으로 분석한 결과 1일 차 및 7일 차의 접속률 차이를 분석한 결과 1일 차에는 두 그룹 간의 접속률 차이가 작지만 7일 차에는 gate_30의 접속률이 gate_40 접속률보다 높아진 경향을 확인했습니다.
분석 결과를 종합적으로 고려할 때 게이트 위치 변경이 1일 차 접속률에는 미미한 영향을 미쳤지만, 장기적으로는 접속률에 영향을 미치고 있으므로 이를 고려하여 게이트 위치를 기존의 레벨 30으로 유지하는 것이 장기적인 접속률을 개선하는데 더 바람직하다고 판단됩니다.
GitHub
https://github.com/hkle2/cookie_cats_project
GitHub - hkle2/cookie_cats_project: cookie cats A/B test dataset analysis project
cookie cats A/B test dataset analysis project. Contribute to hkle2/cookie_cats_project development by creating an account on GitHub.
github.com
'데이터 분석 > 프로젝트' 카테고리의 다른 글
| 국가별 사회경제적 지표 데이터 클러스터링 (5) | 2024.08.30 |
|---|---|
| 넷플릭스 영화 데이터 분석 (7) | 2024.08.02 |
| Kaggle Spaceship titanic 경진대회 (0) | 2024.07.21 |
| 고령 운전자 교통사고 데이터 분석 (0) | 2024.07.15 |
| Olist 이커머스 데이터 분석 프로젝트 (0) | 2024.07.04 |