데이터 세트
Kaggle 우주선 타이타닉 경진대회 데이터 세트
https://www.kaggle.com/competitions/spaceship-titanic/
2912년 우주선 타이타닉은 약 13,000명의 승객들을 태우고 태양계 인근의 거주 가능한 3개의 행성으로 이민을 가는 중이었습니다. 그러나 알파 센타우리를 돌며 첫 번째 목적지인 55 Cancri e로 향하던 중 먼지구름 속에 숨겨진 시공간 이상 현상과 충돌하고 말았습니다. 우주선은 손상되지 않았지만 안타깝게도 거의 절반의 승객들이 다른 차원으로 이동해 버렸습니다. 실종된 승객들을 구출하기 위해 손상된 컴퓨터 시스템에서 복구한 데이터를 바탕으로 어떤 승객이 이상 현상으로 이동했는지 예측해야 합니다!!
데이터 분석
손상된 컴퓨터 시스템에서 두 가지 데이터 세트를 복구했습니다. Train 데이터 세트에는 8,693개, Test 데이터 세트에는 4,277개의 데이터가 들어있습니다. 우주선 타이타닉호의 어떤 승객이 이상 현상으로 이동했는지 예측하기 전에 데이터의 기본 정보를 확인해 보도록 하겠습니다.
Train 데이터 세트

총 14개의 칼럼이 있으며 각 칼럼에 대한 기본 정보와 기술 통계량은 다음과 같습니다.

Test 데이터 세트

총 13개의 칼럼이 있으며 각 칼럼에 대한 기본 정보와 기술 통계량은 다음과 같습니다.
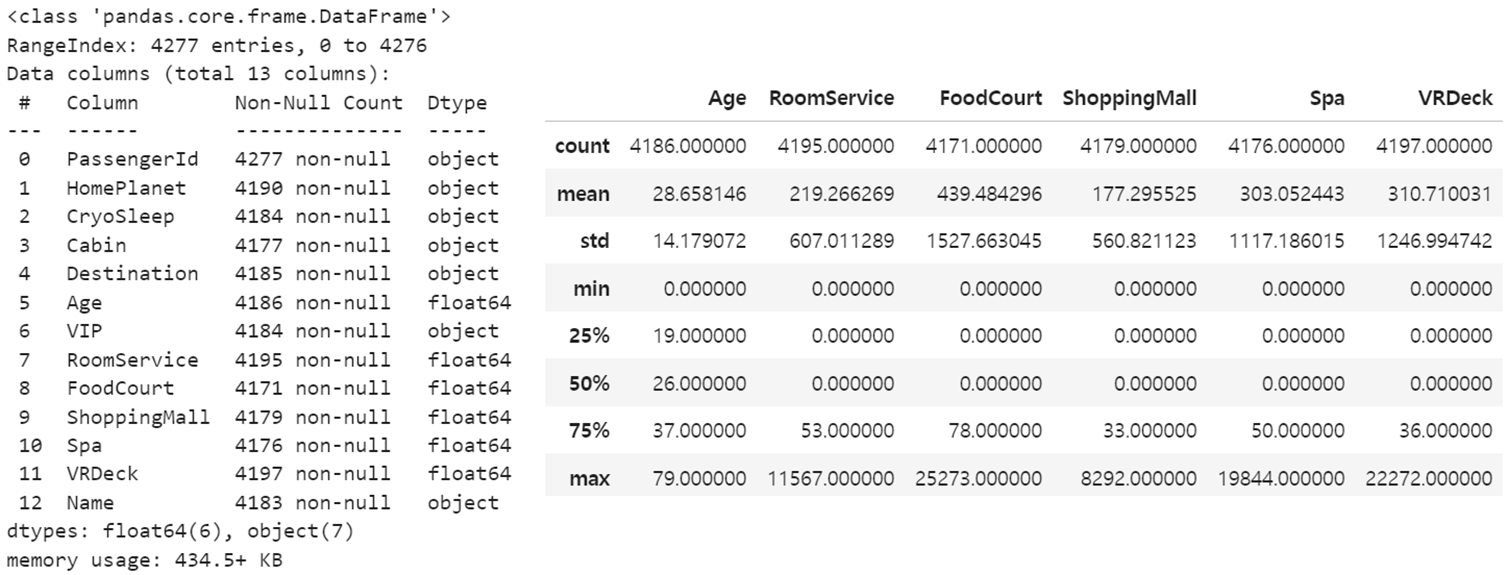
기술 통계량을 살펴보면 RoomService, FoodCourt, ShoppingMall, Spa, VRDeck 칼럼의 최솟값(min), 1사분위수(25%), 중앙값(50%)이 모두 0임을 확인할 수 있습니다. 이는 데이터의 절반 이상이 0이고 일부 값이 매우 커서 이상치로 간주될 수 있다는 것을 나타냅니다.
Train, Test 데이터 세트
분석에 직접적인 연관이 없는 PassengerId와 Name 칼럼, 전처리가 필요한 Cabin 칼럼, 예측해야 하는 Transported 칼럼을 제외한 나머지 칼럼을 조금 더 자세히 살펴보도록 하겠습니다.
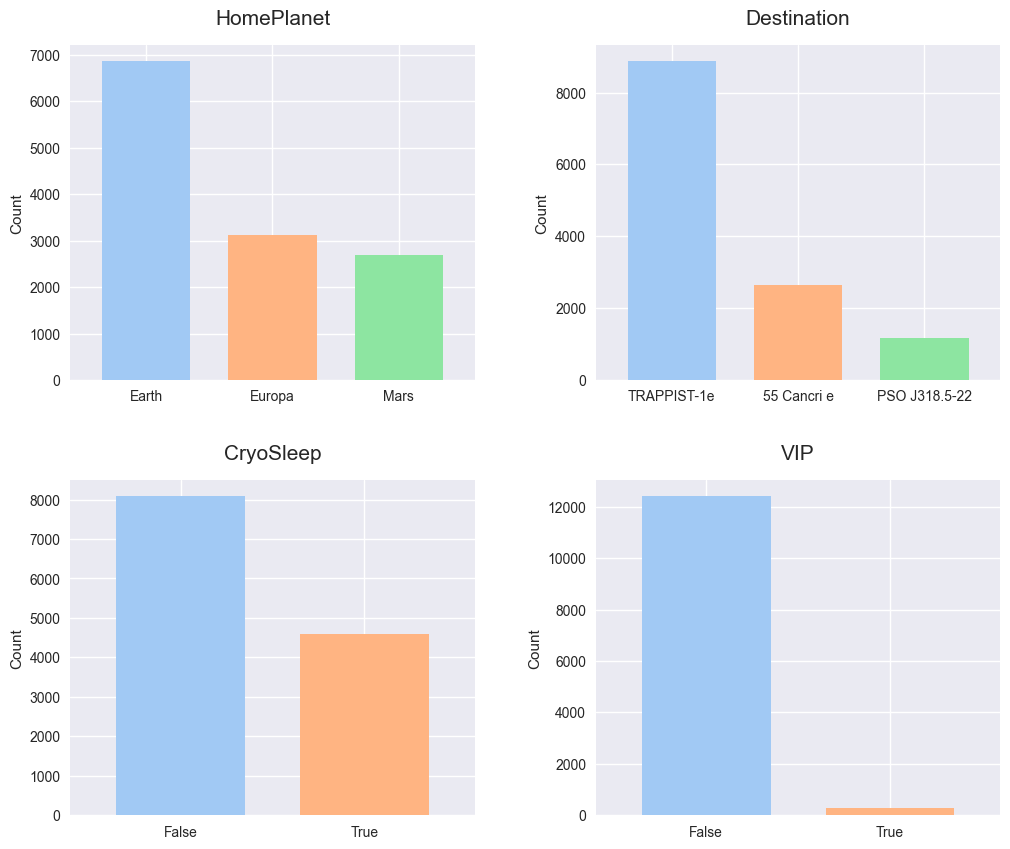

Train 데이터 세트와 Test 데이터 세트를 합쳐 각 칼럼을 시각화해 본 결과 출발지는 Earth, 목적지는 TRAPPIST-1e가 가장 많으며 CryoSleep 상태가 아닌 승객이 더 많고 VIP가 아닌 승객들이 압도적으로 많은 것을 확인할 수 있습니다.
RoomService, FoodCourt, ShoppingMall, Spa, VRDeck 칼럼의 데이터는 기술 통계량에서 확인했던 것과 같이 0에 가까운 값에 집중된 것을 알 수 있습니다. 이는 대부분의 승객이 우주선 내부에서 제공하는 서비스들을 거의 이용하지 않았다는 것을 의미합니다.
Age 칼럼의 히스토그램을 통해 승객들의 연령대는 20대가 가장 많고 나이가 많아질수록 승객 수가 줄어든다는 것도 확인할 수 있습니다.
데이터 전처리
각 칼럼에 대한 기본적인 분석을 마쳤으니 이제 머신러닝 모델을 학습시키기 위해 데이터 전처리를 진행해 보도록 하겠습니다.
데이터 결측값 채우기
먼저 칼럼별 결측값 개수를 확인해 보겠습니다.
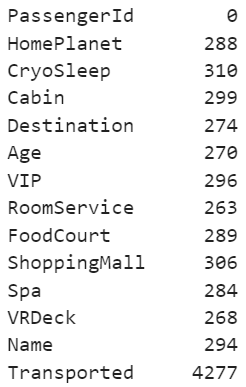
Transported 칼럼은 4,277개의 가장 많은 결측값이 발생했지만, Test 데이터 세트에 승객들의 이동 여부를 나타내는 Transported 칼럼이 없어 자연스러운 현상입니다. 따라서 나머지 칼럼들의 결측값을 채워보도록 하겠습니다.
HomePlanet과 Destination 칼럼의 결측값은 "Unknown"으로 채우고 CryoSleep, VIP, Cabin 칼럼의 결측값은 최빈값으로 채웠습니다. 또한, CryoSleep과 VIP 칼럼의 False와 True 값을 각각 0과 1의 정수형으로 데이터 타입을 변환했습니다.
df["HomePlanet"] = df.HomePlanet.fillna("Unknown")
df["Destination"] = df.Destination.fillna("Unknown")
df["Cabin"] = df.Cabin.fillna(df.Cabin.mode()[0])
df["CryoSleep"] = df.CryoSleep.fillna(df.CryoSleep.mode()[0]).astype(int)
df["VIP"] = df.VIP.fillna(df.VIP.mode()[0]).astype(int)
RoomService, FoodCourt, ShoppingMall, Spa, VRDeck 칼럼의 결측값은 데이터의 통계적 특성을 유지하면서 이상치의 영향을 최소화하기 위해 각 칼럼의 중앙값으로 채웠습니다. Age 칼럼의 결측값은 HomePlanet, Destination, VIP 그룹별 평균값으로 채워 그룹별 특성을 반영하도록 했습니다.
df["RoomService"] = df.RoomService.fillna(df.RoomService.median())
df["FoodCourt"] = df.FoodCourt.fillna(df.FoodCourt.median())
df["ShoppingMall"] = df.ShoppingMall.fillna(df.ShoppingMall.median())
df["Spa"] = df.Spa.fillna(df.Spa.median())
df["VRDeck"] = df.VRDeck.fillna(df.VRDeck.median())
df["Age"] = df.Age.fillna(df.groupby(["HomePlanet", "Destination", "VIP"])["Age"].transform("mean"))
다음으로 PassengerId와 Cabin 칼럼의 데이터를 분리하여 새로운 칼럼을 생성했습니다. PassengerId 칼럼의 데이터는 그룹ID_번호 형식으로 되어 있어 그룹ID만 분리하여 GroupID 칼럼을 만들어주었습니다. Cabin 칼럼의 데이터는 객실의 층/번호/위치 형식으로 이루어져 있어 이를 분할하여 Deck, Num, Side 칼럼을 생성했습니다.
df["GroupId"] = df.PassengerId.apply(lambda x: str(x).split("_")[0]).astype(int)
df[["Deck", "Num", "Side"]] = df.Cabin.str.split("/", expand=True)
분석에 직접적인 연관이 없는 Name 칼럼과 데이터를 분리해 준 Cabin 칼럼을 삭제해 주고 칼럼별 결측값 개수를 다시 확인해 보면 결측값이 모두 채워진 것을 확인할 수 있습니다.
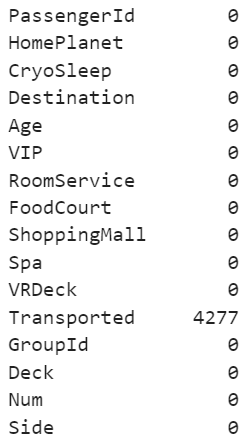
데이터 스케일링
결측값을 모두 채운 현재 데이터 세트에서 범주형 데이터와 연속형 데이터를 구분하고 적절한 전처리를 적용해 보도록 하겠습니다. HomePlanet, Destination, CryoSleep, VIP, GroupID, Deck, Num, Side, Transported는 범주형 데이터이며 Age, RoomService, FoodCourt, ShoppingMall, Spa, VRDeck은 연속형 데이터입니다. 범주형 데이터에는 One-Hot Encoding을 적용해 주고 연속형 데이터에는 Robust Scaler와 Standard Scaler를 사용하도록 하겠습니다.
df = pd.get_dummies(df, columns=["HomePlanet", "Destination", "Deck", "Side"], dtype=int)
df = df.drop(["Num"], axis=1)
HomePlanet, Destination, Deck, Side 칼럼에 One-Hot Encoding을 적용하고 Num 칼럼은 삭제했습니다. Num 칼럼에는 총 1,894개의 객실 번호가 있어 모델 학습에 유의미한 정보를 제공하지 않고 오히려 과적합(overfitting)의 위험성을 증가시킬 수 있어 삭제했습니다.
df[["RoomService", "FoodCourt", "ShoppingMall", "Spa", "VRDeck"]] = robust_scaler.fit_transform(df[["RoomService", "FoodCourt", "ShoppingMall", "Spa", "VRDeck"]])
df[["Age"]] = standard_scaler.fit_transform(df[["Age"]])
RoomService, FoodCourt, ShoppingMall, Spa, VRDeck 칼럼의 데이터는 이상치가 많아 Robust Scaler를 사용해서 스케일링을 해주고 Age 칼럼의 데이터는 정규분포에 가까워 Standard Scaler를 사용해서 스케일링을 해줬습니다.
전처리를 모두 마친 데이터를 다시 Train 데이터 세트와 Test 데이터 세트로 분리하여 저장했습니다.
모델 학습 및 예측
Train 데이터 세트를 사용하여 모델을 학습하고 Test 데이터 세트로 예측하여 Kaggle에 제출해 보겠습니다.
Decision Tree Classifier
먼저 Decision Tree Classifier 모델을 사용해서 학습해 보겠습니다. 하이퍼 파라미터를 기본값으로 설정한 상태에서 모델을 학습시킨 후 Stratified K-Fold 교차 검증을 통해 평가한 결과 74.9%의 정확도를 보였습니다.
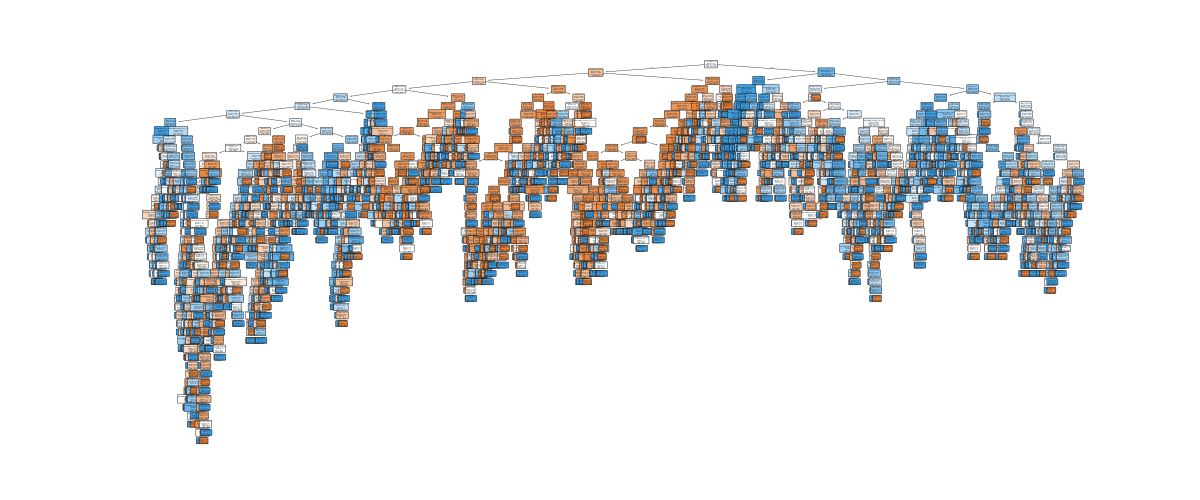
시각화 결과 모델이 과적합 된 것을 확인할 수 있습니다. 하이퍼 파라미터 튜닝을 통해 적절한 파라미터 값을 찾아 모델을 다시 학습해 보겠습니다. 하이퍼 파라미터 튜닝 방법으로는 Grid Search와 Random Search을 사용했습니다.
Grid Search와 Random Search로 찾은 파라미터로 모델을 학습시킨 후 Stratified K-Fold 교차 검증을 통해 평가한 결과 모두 77.9%의 정확도를 보였습니다.
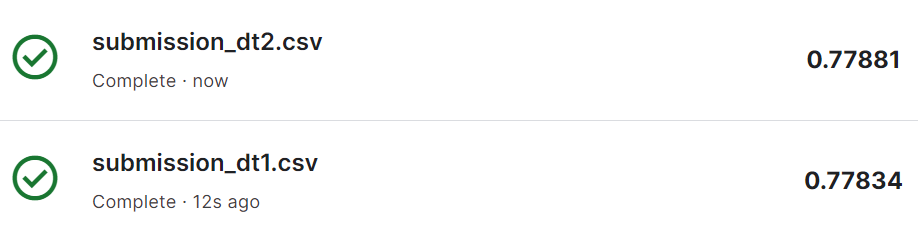
두 가지 예측 결과를 Kaggle에 제출해 본 결과 77.8%에서 77.9%의 정확도를 기록했습니다!!
약간 더 높은 정확도를 보인 Random Search로 찾은 파라미터로 학습한 모델의 Feature Importance를 시각화해 보았습니다.

CryoSleep의 기여도가 상당히 큰 반면 일부 칼럼은 기여도가 매우 낮은 것을 확인할 수 있습니다. 기여도가 0.004 이하인 하위 10개의 칼럼을 삭제한 후, Random Search로 하이퍼 파라미터 튜닝을 하고 모델을 다시 학습했습니다.

그러나 Kaggle에서 76.1%의 정확도를 기록하며 이전에 제출했던 것보다 정확도가 낮아진 것을 확인할 수 있습니다 😭😭
Random Forest Classifier
두 번째로 성능을 향상하고 과적합을 줄이는 데 유리한 앙상블 기법인 Random Forest Classifier 모델을 사용해 보겠습니다. 하이퍼 파라미터를 기본값으로 설정한 상태에서 모델을 학습시킨 결과 Stratified K-Fold 교차 검증을 통해 80.2%의 정확도를 보였습니다. 이전 모델보다 높은 정확도를 기대할 수 있을 것 같습니다!!
과적합을 방지하고 모델 성능을 더욱 향상하기 위해 하이퍼 파라미터 튜닝을 통해 적절한 파라미터 값을 찾아 모델을 다시 학습해 보겠습니다. Grid Search로 찾은 파라미터로 모델을 학습시킨 후 Stratified K-Fold 교차 검증을 통해 평가한 결과 80.9%의 정확도를 보였고 Random Search로 찾은 파라미터로 모델을 학습시킨 후 Stratified K-Fold 교차 검증을 통해 평가한 결과도 80.9%의 정확도를 보였습니다.
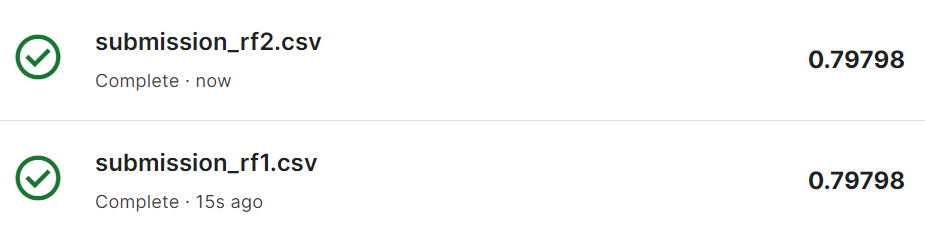
두 가지 예측 결과를 Kaggle에 제출해 본 결과 79.8%의 정확도를 기록했습니다!!

약간 더 높은 정확도를 보인 Random Search로 찾은 파라미터로 학습한 모델의 Feature Importance를 시각화해 보았습니다. 이번 모델에서는 GroupID의 기여도가 가장 크며 Decision Tree Classifier 모델보다 기여도가 보다 균등하게 분산된 경향을 확인할 수 있습니다.
기여도가 0.001 이하인 하위 10개의 칼럼을 삭제한 후, Random Search로 하이퍼 파라미터 튜닝을 하고 모델을 다시 학습했습니다.

Kaggle에서 79.8% 정도의 정확도를 기록하며 이전에 제출했던 것과 유사한 정확도를 확인할 수 있습니다.
LightGBM
마지막으로 LightGBM 모델을 사용해 보겠습니다. LightGBM은 빠른 학습 속도와 높은 정확도로 대규모 데이터 세트에서 특히 효과적인 모델로 알려져 있습니다. 기본 하이퍼 파라미터를 사용하여 모델을 학습한 결과 80.5%의 정확도를 보였습니다. 최적의 하이퍼 파라미터를 찾아 학습한다면 높은 정확도를 기대할 수 있을 것 같습니다!!
과적합을 방지하고 모델의 성능을 더욱 향상하기 위해 하이퍼 파라미터 튜닝을 통해 적절한 파라미터 값을 찾아 모델을 다시 학습해 보겠습니다. Grid Search로 찾은 파라미터로 모델을 학습시킨 후 Stratified K-Fold 교차 검증을 통해 평가한 결과 80.9%의 정확도를 보였고 Random Search로 찾은 파라미터로 모델을 학습시킨 후 Stratified K-Fold 교차 검증을 통해 평가한 결과도 80.5%의 정확도를 보였습니다. 기본 하이퍼 파라미터를 사용한 모델도 높은 정확도를 나타내어 3가지 예측 결과를 모두 Kaggle에 제출해 보겠습니다.
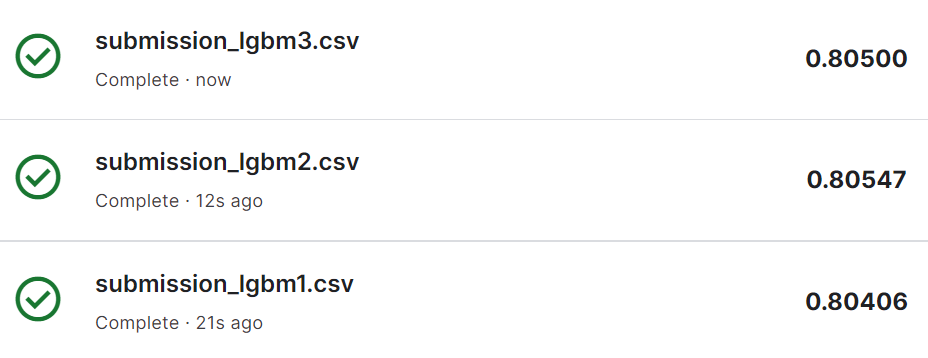
세 가지 예측 결과를 Kaggle에 제출해 본 결과 Random Search로 찾은 파라미터로 학습한 모델이 가장 높은 정확도를 보였습니다.
이번에는 기여도가 낮은 칼럼을 삭제하지 않고 하이퍼 파라미터를 직접 조정해 보며 학습하고 정확도를 확인해 보겠습니다.

다양한 하이퍼 파라미터로 모델을 학습하고 Kaggle에 제출한 결과 80.8%의 정확도를 기록했습니다!! 🎉🎉
머신러닝 모델 최종 예측 결과
지금까지 Decision Tree Classifier, Random Forest Classifier, LightGBM의 세 가지 모델을 사용하여 결과를 예측하고 Kaggle에 제출해 보았습니다. 이 중 LightGBM으로 학습한 모델이 가장 높은 정확도를 기록했으며 Kaggle 제출 결과 80.8%의 정확도로 180위를 달성했습니다!!

'데이터 분석 > 프로젝트' 카테고리의 다른 글
| 국가별 사회경제적 지표 데이터 클러스터링 (5) | 2024.08.30 |
|---|---|
| Cookie Cats A/B 테스트 데이터 분석 (0) | 2024.08.08 |
| 넷플릭스 영화 데이터 분석 (7) | 2024.08.02 |
| 고령 운전자 교통사고 데이터 분석 (0) | 2024.07.15 |
| Olist 이커머스 데이터 분석 프로젝트 (0) | 2024.07.04 |